~ 7 min read
How to run a local LLM for inference with an offline-first approach

The Large Language Model (LLM) hype train is in full swing even two years after the release of the ChatGPT app by OpenAI on November 2020. LLMs have revolutionized the field of natural language processing and are now being used in a wide range of applications, from chatbots to code generation (a la GenAI and what you’ve come to know as GitHub Copilot). However, running an LLM can be computationally expensive, or incur high subscription costs if LLMs are the underlying engine of your business. There are, of course, other reasons that warrant running an LLM locally, such as data leak and privacy concerns of LLMs, but this article will focus specifically on the task of how to run a local LLM for inference.
To set the stage first, let’s define what an LLM is, how it works, and what are some of its components.
What is a Large Language Model (LLM)?
An LLM is a type of machine learning model that is trained on a large amount of text data. Three key pieces make up LLMs and they are (1) the data which the model is trained on; (2) the architecture of the model (such as Transformer, GPT, BERT, etc.), and (3) the training process. With each iteration of training, the model learns to generate text by predicting the next word in a sequence of words, sequentially improving itself until it ends up generating text that is indistinguishable from human-written text - coherent and contextually relevant.
What is inference?
Inference is the process of using a trained model to generate text. In essence, you can think of inference as another iteration of its last training state but now it handles live data, where the goal is the model’s ability to generate text based on the information it has learned during training. In the context of LLMs, inference involves feeding a prompt to the model and having it generate text based on the prompt. The model generates text by predicting the next word (technically, a token) in the sequence.
How to run a local LLM for inference
There are several tools that wrap LLMs and provide the ability to run them locally and interact with them (the inference process, as we described above), most notably these are:
- Ollama: the ollama open-source project has installers for macOS, Windows, and Linux. It is a simple and easy-to-use tool that allows you to run LLMs locally and interact with them via a command-line interface (CLI) for the chat aspect. Ollama supports several LLM models such as Llama 3, Phi3, Gemma, mistral and others. It is by far the easiest way to run an LLM locally for inference if you are looking for a simple CLI tool. Bonus, the Ollama tool also provides a REST API with similar signature as that of OpenAI API and also features a Docker image for easy deployment.
- Open WebUI: this was formerly known as Ollama WebUI but has since been renamed to Open WebUI. Open WebUI, another open-source project, featuring a rich ChatGPT-like interface with options to provide context through file upload, includes a UI for a chat interface, saved history, as well as downloading and managing LLM models.
- Chatty UI: a new open-source project by Addy Osmani and Jake Hoeger, Chatty UI is a web-based LLM tool that not only allows you to run LLMs locally but is also entirely built and based on the browser for the inference due to the WebGPU API. This opens a great new way to run LLMs natively in the browser (they are downloaded to the browser cache and IndexDB) and no other software installation is required.
- Llama.cpp: llama.cpp is a C++ library that allows you to run LLMs locally and interact with them via a command-line interface (CLI). It is a more advanced tool than Ollama and provides more control over the LLMs you run locally and is aimed at having better performance. Llama.cpp supports several LLM models such as Llama 3, Phi3, Gemma, mistral and others. It is a great tool if you are looking for more control over the LLMs you run locally and more specifically will be useful if you plan to interface with LLMs over library bindings in C++.
- LM Studio: the LM Studio is another all-in-one rich web interface and LLM management tool that allows you to run LLMs locally from Hugging Face marketplace and interact with them via a web-based interface. LM Studio however, is not open-source.
All of these projects are open-source and free to use.
The way that I have been experimenting with an offline-first approach to running LLMs locally is by combining the Ollama tool with the Open WebUI project. This allows me to run LLMs locally and manage that through the Ollama installer, and for the rich UI interaction part I use Open WebUI that exposes an intuitive ChatGPT-like web-based interface. This is made especially accessible because the Open WebUI project allows to specify a remote REST API for the inference process, so you can plug it into the stock OpenAI API or a locally running LLM, which in my case, that’s Ollama.
How to install Ollama
Getting Ollama up and running is a breeze. You can install Ollama by following these steps:
- Go to the Ollama open-source project on GitHub and download the installer for your operating system. In my case it’s a macOS installer and you end up with a
Ollama-darwin.zipartifact after downloading. - Extract the downloaded zip file and you will find the
Ollamabinary inside the extracted folder. - Copy the
Ollamabinary to your macOSApplicationfolder and run it from there.
Once you run the Ollama installer from the Application folder you’ll get the first-time setup wizard which guides you through to installing the ollama command-line tool in your path. After the installation is complete, you can run the ollama command from the terminal to start the Ollama tool. As easy as:
ollama run llama3If you want a smaller model you can run the 128k context window version of the Phi3 model from Microsoft Research by running
ollama run ollama run phi3:3.8b-mini-128k-instruct-q4_1.
And just like that, you have a local LLM running on your machine. Here’s how it looks:

As you can see, this model is quite biased and censored so we can’t easily get it to help us hack the planet. But, good thing we can run any model we want, eh? ;-)
How to install Open WebUI
So yeah, you can keep interacting with your LLM model of choice via the Ollama CLI interface but that’s not really sustainable for a long time use. That’s where the Open WebUI project comes in. You can install Open WebUI using the Docker image provided by the project. As easy as running this one-off command:
docker run -d -p 3000:8080 -e WEBUI_AUTH=False --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainAnd then you can access the Open WebUI interface by navigating to http://localhost:3000 in your browser. Here’s how it looks:
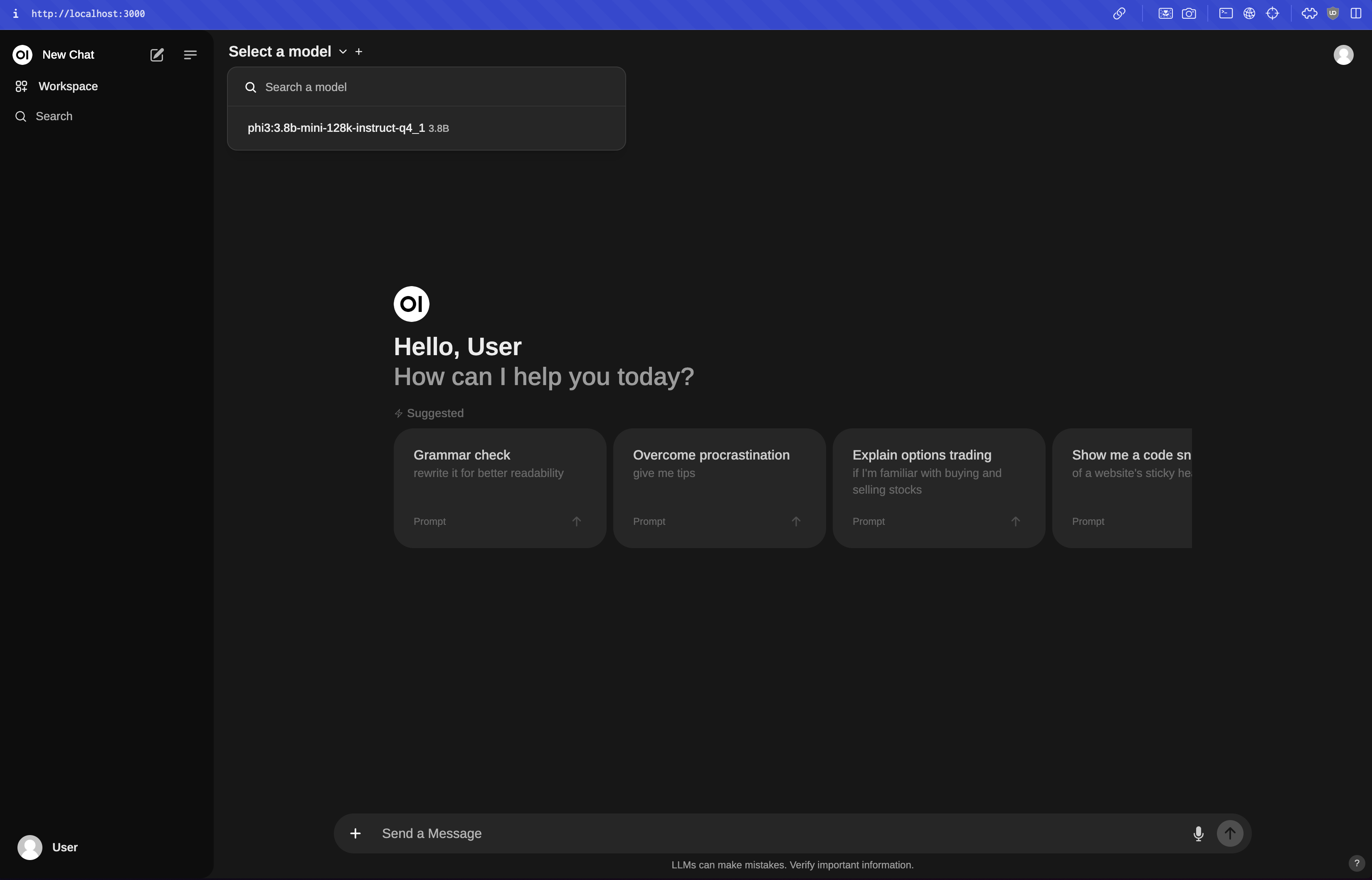
The above Docker command uses the command-line flags to do the following:
- Start a local server on port 3000 (bound to the internal 8080 port of the Open WebUI application running inside the container)
- Disable authentication for the Open WebUI interface (by setting
WEBUI_AUTH=Falseenvironment variable) - Add a host entry to the container so that it can communicate with the host machine (by setting
--add-host=host.docker.internal:host-gateway) - Mount a volume to store the data generated by the Open WebUI application (by setting
-v open-webui:/app/backend/data) - Runs in the background
Local-first Code Assistants
Some emerging tooling in this space, if you wish to swap out enterprise-level code assistants like GitHub Copilot, OpenAI Codex, or Google’s Gemini, are:
- Continue.dev for the overall IDE integration,
ollamaas a local LLM inference and model management, anddeepseek-coder 6.7bfor the model. - The
Codestralmodel has also been gaining traction in the local-first code assistant space, and you can test it in the HugginFace model hub.
Conclusion
I highly recommend you experiment with local-first LLMs for your general-purpose chat, code generation, and other text-based tasks. It’s a great way to learn about the inner workings of LLMs and how they are used in practice. The ecosystem support is very mature with great developer experience tooling and the tools I mentioned in this article are a great starting point for running LLMs locally.
That’s it. Hack the planet!
