~ 7 min read
GenAI Predictions and The Future of LLMs as local-first offline Small Language Models (SLMs)

We’ve been increasingly accustomed to subscription-based economic model, which did not skip the GenAI hype, but there are other costs to online remote LLMs and the future, I believe, is in offline Small Language Models (SLMs). That is, until our local devices are capable enough to hosting Large Language Models (LLMs) locally, or the architecture enables hybrid inference.
From Midjourney, taking the world by storm to generate visual content, to ChatGPT itself and other GenAI and LLM use-cases, all fall into the business model of a subscription service. Surprising? not really, given that the tech industry is obsessed with SaaS ever since Salesforce CEO Marc Benioff have championed it nonstop.
However, running GenAI tools in a subscription-based model has more hidden costs than just recurring billing invoices to pay, and this is what I want to discuss in this article and why the future of LLMs lies in an offline-first inference capability approach, perhaps pioneered first with Small Language Models (SLMs) until hardware catches up.
I’m seeing more and more validation and use-cases for running private, local-first LLMs.
The hidden costs of online third-party LLMs
Let’s break-down the hidden costs of online, remote hosted LLMs, and the challenges of wide-spread adoption that concern business leaders. Most specifically, these issues are centered around the problem of the GenAI service being hosted and owned by a third-party, and the implications of that. As such, there are security risks, such as prompt injection, that are orthogonal to the decision of self-hosting or using a third-party service.
1. Privacy
The most obvious cost of online, remotely hosted LLMs by a third-party is privacy.
Whether you’re using a GenAI code assistant tool like GitHub Copilot, or having a general-purpose chat session with OpenAI’s ChatGPT or Google’s Gemini, you’re sending your data to a remote server, which is then processed by the LLM, and the results are sent back to you. This is a privacy nightmare, especially when you consider the fact that LLMs are trained on vast amounts of data, including personal information. Suddenly, concerns such as the following arise:
- Do these companies use the data I send to them for training their models further?
- What if the data I send to them is sensitive? PII data, or confidential information?
- What if the data I send to them is proprietary? Will they use it to their advantage? Or worse, could that data leak into the model and then shared with my competitors?
To solve the really challenging and deeply-rooted business problems, you need to provide that very sensitive data to the LLM as context. Yet doing so, is a hard pill to swallow for many business leaders, especially in the financial, healthcare, and legal sectors. Tech companies are often early adapters, but even they are not rushing too quickly to adopt code assistant tools like Copilot, exactly for these reasons.
2. Security
When it comes to security aspects of using a third-party LLM service, the main concern involves the service provider which becomes an external attack surface.
Your organization’s attack surface expands to include the service provider’s infrastructure and systems, being OpenAI and Anthropic as primary examples. Any security vulnerabilities or misconfigurations in the service provider’s environment could potentially be exploited by attackers to gain unauthorized access or conduct other malicious activities. These risks directly impact their customers - you.
Have doubts on how probable security issues are for OpenAI? Let’s review a few:
- Here’s OpenAI write-up from March 2023 on ChatGPT first security breach and outage. The underlying issue was due to the open-source Redis client library
redis-py. Sonatype offered a detailed analysis on the redis-py vulnerability. - The
redis-pyvulnerability was also a contributor to ChatGPT account takeover attacks.
More chatter on Reddit discussion with regards to security concerns of third-party hosted LLMs is also worth reviewing.
3. Data leakage
From a developer perspective, a generative AI code assistant took like GitHub Copilot feels like magic sometimes, and a lot of that is due to the fact that it has access to the project’s code as context, which allows it to generate code that is more relevant and accurate. At the same time, this also means that the code you’re working on is sent to a remote server, which is then processed by the LLM on GitHub servers.
It’s not just code you and your colleagues are working on that is sent to the remote server, but also the sensitive API tokens, certs, password and other information that lives in the code project on those .env files and configuration files.
4. Latency and availability
As LLM usage increase as a foundational API for many applications, the latency and availability of the service become a critical factor. In some business cases, the latency of the service can be a deal-breaker, or a make-or-break factor for the user experience and the overall capability of the application.
For example, if you’re building a real-time chatbot to replace support, telemarketing and such, you can’t afford to have a high latency, as it will make the conversation feel unnatural and frustrating for the user. For a text-based conversation, that to an extent is somewhat tolerable, but what about the future of voice-based conversational AI? The latency will be even more critical and easily noticeable.
Availability is another issue and not one to be taken lightly. LLM services can get disrupted, even with major players like OpenAI, Google, and Microsoft. From an operational perspective, it’s not a question of if, but when, the service will be disrupted. And when it does, it can have a cascading effect on the applications that rely on it, causing a domino effect of failures.
In fact, here’s the past 90 days availability of OpenAI services, as reported by status.openai.com and in adjacent to writing this blog post:
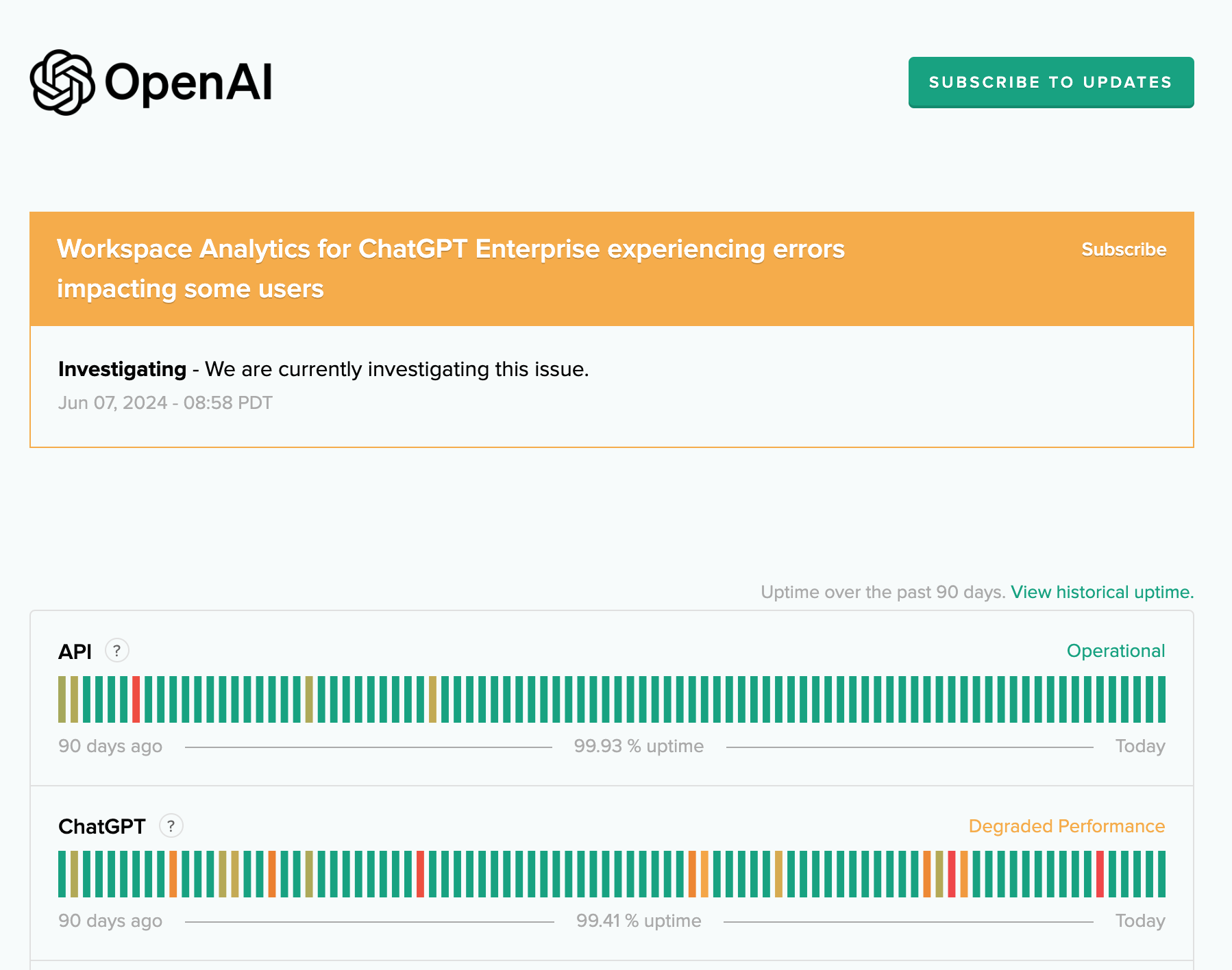
On June 4th, 2024, ChatGPT had an outage that last for a few hours during Tuesday and impacted ChatGPT. Previously, this happened in November 2023 when a ChatGPT outage lasted for 90 minutes and included disruption of OpenAI API services too.
The rise of offline Small Language Models (SLMs)
Developers and tech workers in general, are often characterized as owners of very capable hardware and these days a house-hold MacBook Pro and other laptops can easily run an 8B parameters Small Language Model (SLM) locally with good inference speed. This is a game-changer, as it allows developers to run LLMs locally, without sending their data to a remote server, and without having to worry about the privacy, data leak, and security implications of doing so.
From Ollama, to llama.cpp and other open-source projects, the rise of offline-powered LLM inference is growing in adoption.
Predictions and future outlook
- Local-first, Hybrid-capable and Edge-inference LLMs: The future of LLMs is in local-first offline inference, with a hybrid-capable remotely hosted over a network, and edge-inference deployed LLMs.
- Open-source & Open LLMs: The pre-training of LLMs will be done by large tech companies, but the fine-tuning phase and deployment will be done by developers and businesses, due to being less costly and demonstrating great ROI. Foundational pre-trained models will be open-sourced and available for fine-tuning, deployment, and scrutiny of the model’s training data, weights and biases.
- Consumer-grade GPU acceleration: The widespread adoption of local-first inference will further push GPU acceleration and inference compute capabilities to exist as a first-class hardware in consumer-grade devices. Just as we’re taking GPS and WiFi chips for granted in end-user consumer devices, we’ll take GPU acceleration for granted in the future.
- Micro Fine-Tuning model training: Fine-grained model training is already becoming a norm, with a model like
deepseek-coder 6.7bwhich is fine-tuned for specific code generation tasks. My prediction here is that the next evolution of this will be micro fine-tuning (MFT) which will create even more specialized models such as a code generation model for specific languages (JavaScript, or Python) and specialized frameworks and tooling (think React, or Django).
Where we go from here is a future where LLMs and GenAI are not just a tool for developers, but a tool at everyone’s disposal and widely deployed. Hopefully in a more resilient, secure, privacy-aware, and responsible manner.
